

Got questions about how we work?
Here are some of the most common ones we get.
While defining precise percentages would be difficult, autonomous agents can reliably and quickly handle reconnaissance, attack surface mapping, payload generation, and exploit chain development for web applications and API surfaces with predictable structures.
That said, very few models can understand what your application is supposed to do before recognizing that it's doing something wrong. Business logic flaws, multi-hop privilege escalation across services, and payment flow manipulation still require human review by experts who've spent time understanding your architecture.
The more useful framing here, thus, maybe "what does human time get freed up for?" If agents absorb 50% of the mechanical work, your security team stops spending time on known CVE sweeps and starts spending it on the attack paths that actually keep you up at night.
What autonomous agents handle well today (percentages as estimates):
Recon & asset discovery ████████████████░░░ 85%
Known CVE exploitation ██████████████░░░░░ 75%
Misconfiguration detection █████████████░░░░░░ 70%
Auth & token flow testing ████████████░░░░░░░ 65%
What still needs humans:
Business logic abuse ████░░░░░░░░░░░░░░░ 20%
Chained novel attacks ███░░░░░░░░░░░░░░░░ 15%
Zero-day discovery █░░░░░░░░░░░░░░░░░░ 5%
Astra's autonomous pentesting sits at the higher end of the automated range for web apps, trained on patterns from 5,000+ real-world pentests, so the agent army doesn't have to start from scratch on every engagement.
Useful, genuinely. But the gap between the demo and what runs on your actual infrastructure is wider than most vendors will admit before you sign.
Here's what holds up in production: recon at scale, attack surface mapping, exploitation of known vulnerabilities, and chained findings across predictable structures. For web applications with standard authentication flows and documented API surfaces, autonomous agents consistently find real vulnerabilities fast, i.e., confirmed exploits with proof.
Here's what doesn't hold up yet: anything requiring the agent to understand business intent. An agent can find that your /api/orders/{id} endpoint doesn't validate ownership. It can't independently reason that the order ID format reveals your daily transaction volume, that your mobile app calls this endpoint with a long-lived token, and that combining these three observations creates a fraud vector specific to your business model. That still needs a human who knows your product.
The community debates on r/Pentesting and r/netsec have largely moved past "is this real" and landed on "what exactly is it good for." That's the right question. The answer is: a lot, within specific boundaries, and increasingly more as the tooling matures.
Astra's autonomous pentesting is trained on patterns from 5,000+ real pentests and 10 million+ vulnerabilities, so the agent army doesn't reason from first principles in every engagement. The patterns are baked in, something that finds real issues on day one.
False positives are the original sin of security tooling, and autonomous pentesting is not immune. The question is how a platform handles them, because "we have low false positives" is a claim every vendor makes, and almost none of them explain the mechanism behind it.
The mechanism that actually works is exploit-level proof: "here is the payload, here is the response, here is the data that came back." If a platform can show you the exact HTTP request that worked, the response that confirmed exploitation, and a reproducible set of steps to trigger it again, the finding is real. If it can only show you a confidence score and a CVE reference, it's a scanner with a better UI.
http
# What a false positive looks like:
GET /api/users?id=1 UNION SELECT null--
Response: 500 Internal Server Error
Finding: [HIGH] Possible SQL injection detected
Confidence: 72%
\
# What proof of exploitation looks like:
GET /api/users?id=1 UNION SELECT username,password,null FROM users--
Response: 200 OK
Body: [{"username":"admin","password":"$2b$12$hashed..."}]
Finding: [CRITICAL] Confirmed SQL injection — admin credentials extracted
Proof: Request + response attached, steps to reproduce included
Astra Security runs a dedicated validator AI on every finding before it appears in your report: two varied armies of agents to find and map the attack vectors (along with vulnerabilities), while a separate AI validates for false positives by actually exploiting it.
The practical implication for your team is that you're triaging confirmed exploits, with key fixes to break each chain, instead of chasing an unending laundry list of vulnerabilities.
Autonomous pentesting proves its value when it chains together known vulnerability patterns into something real and exploitable that we might otherwise miss because we stop one step too early. It is persistent where humans are inconsistent, methodical where we get tired.
Zero-days and select few business logic chains: not yet, and any vendor telling you otherwise is overselling.
The distinction matters because these are fundamentally different problems. Chaining known vulnerabilities is a reasoning-and-sequencing problem, i.e., the agent needs to recognize that finding A enables finding B. Modern autonomous agents handle this reasonably well, especially when trained on real exploitation patterns rather than synthetic data.
True zero-days, i.e., vulnerabilities requiring genuinely novel hypotheses that no training set has seen, are still out of reach for autonomous systems. But a lot of what gets called a zero-day is simply a flaw that existed from day one and was never found, meaning, autonomous agents, running continuously across every endpoint and edge case, find those regularly.
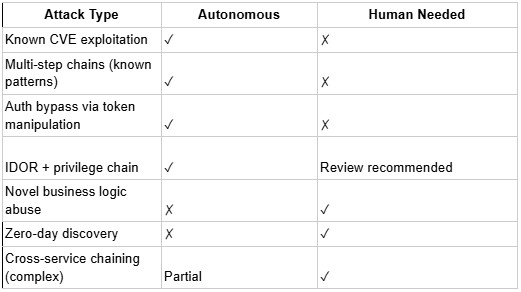
Astra's two testing modes address this split directly. The structured pentest agents work through every known attack scenario systematically, while the bounty hunter agents pursue the most critical vulnerability by whatever path leads there, which often uncovers chained paths through completely unexpected routes.
Neither mode discovers true zero-days, but together they cover the known-pattern space more thoroughly than a human team working against time constraints.
What's coming: multi-target and cross-target testing on the roadmap will allow attack chains to span across services rather than within a single application. That significantly expands what autonomous chaining can find.
This is the question that separates engineers who've actually built with these systems from people who've only seen the demos. Loop and memory issues are real, they're common in less mature implementations, and they're worth asking about before you put any autonomous tool near your infrastructure.
The failure modes show up in a few predictable ways. State drift occurs when an agent loses track of what it has already tested and starts re-probing the same endpoints in a loop: generating noise and wasting testing time.
Hallucinated target states happen when an agent incorrectly concludes an endpoint responded in a way it didn't and builds subsequent attack steps on a false premise. Missing termination criteria means an agent keeps running after it should have stopped, either because it has no clear "done" signal or because it encounters a condition it wasn't trained to recognize.
python
# What a naive agent loop looks like without state management:
while not done:
endpoint = select_next_target() # No memory — picks same endpoint
result = probe(endpoint) # Re-probes endlessly
if result.interesting:
findings.append(result) # Duplicates accumulate
# done never becomes True — no termination criteria
# What a governed agent loop looks like:
state = RedisBlackboard() # Shared state across agents
retry_budget = RetryBudget(max=3) # Explicit retry limits
while not state.is_complete():
endpoint = state.next_untested() # Only untested endpoints
result = probe(endpoint)
state.mark_tested(endpoint, result) # Persist state immediately
if retry_budget.exceeded(endpoint):
state.skip(endpoint) # Hard stop on retry limit
if result.has_proof():
validator.confirm(result) # Validate before surfacing
Astra handles this through checkpointing built into multiple levels of the agent architecture, explicit scope enforcement that prevents agents from retesting outside defined boundaries, and a separate validator that surfaces findings only after exploitation is confirmed, serving as a natural termination gate. If a finding can't be proven, it doesn't appear in your report, and the agent moves on.
The OWASP Autonomous Penetration Testing Standard (APTS) — which Astra's team helped spearhead— formalizes governance requirements for exactly these failure modes, including scope enforcement, human override controls, and auditability of agent decisions.
It's worth asking any vendor you evaluate whether their platform aligns with APTS before you hand it access to production systems.
It depends on what the tool is doing at any given moment, and any platform that gives you a blanket "yes, totally safe on production" without qualification is one you should push back on hard.
That said, passive, non-disruptive checks (such as asset discovery, certificate scanning, configuration validation, known CVE fingerprinting, and traffic analysis) can run safely in production with proper scope controls.
But active exploitation, fuzzing, payload injection, and auth-bypass attempts belong in a staging environment that mirrors production, using sanitized data. Not because autonomous tools are inherently dangerous, but because offensive tooling is designed to find edge cases, and your production system has real edge cases that serve real users.
All of which are documented failure modes from teams that ran exploitation-grade testing against live infrastructure without proper guardrails.
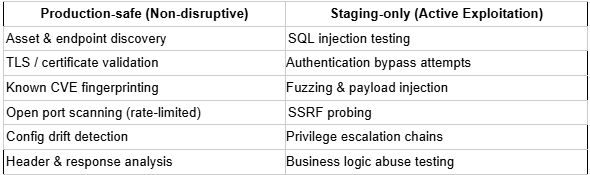
Astra’s AP enforces this at the architecture level. Scope is strictly defined at setup: agents test only the specified target with the provided credentials, with stringent guardrails that prevent testing outside those boundaries at multiple checkpointing layers.
When configuring your target, Astra lets you designate the environment as production or staging which directly influences how the agents behave. For teams running our autonomous pentesting platform against production, configure asset discovery and continuous configuration monitoring as your always-on layer, and use the staging selector to schedule active exploitation runs against your staging environment on every significant deploy or on a defined cadence.
This helps you get continuous visibility without putting live user traffic at risk.
Scoping is where most teams underinvest, and it's where most production incidents blamed on "the tool" actually originate. This is where a rules of engagement (ROE) document comes in, which should answer six questions before a single agent runs:
1. What is explicitly in scope? Define target URLs, IP ranges, API endpoints, and authentication contexts. Be specific: "the production web application" is not a scope definition. app.yourcompany.com, api.yourcompany.com/v2, and the authenticated session for testuser@yourcompany.com is.
2. What is explicitly out of scope? Third-party services your application calls, shared infrastructure used by other teams, any endpoint that writes to a production database, payment processors, and anything with an SLA you can't afford to touch.
3. What action types are permitted? Read-only reconnaissance only, or active exploitation? Credential testing against real accounts, or synthetic test users only? Define this per environment, not globally.
4. What are the rate limits? How many requests per second are acceptable before you risk triggering WAF blocks, rate limiting, or alerting your own monitoring? Set this explicitly.
5. Who approves high-impact actions? Any finding that could cause data modification, account lockout, or service disruption should require a human approval step before the agent proceeds. Build that gate in before you need it.
6. What is the escalation path if something goes wrong? Who gets paged if an agent triggers an unintended outage? What's the rollback procedure? This is the question nobody answers until 2 am when they need it.
yaml
# Example ROE configuration (simplified):
scope:
targets:
- url: "https://staging.yourapp.com"
environment: staging
exploitation: full
- url: "https://app.yourapp.com"
environment: production
exploitation: passive_only
exclusions:
- "https://payments.stripe.com/*"
- "https://yourapp.com/admin/delete*"
- pattern: ".*destructive.*"
rate_limits:
requests_per_second: 10
concurrent_agents: 5
max_runtime_hours: 4
permissions:
credential_testing: synthetic_users_only
data_modification: never
high_impact_actions: require_human_approval
escalation:
primary_contact: "security@yourcompany.com"
pagerduty_policy: "P3-security-incidents"
auto_pause_on: ["5xx_spike", "login_lockout_detected"]
Astra handles scope enforcement structurally: agents cannot test outside the defined target; scenario limits are set per plan; and the platform checkpoints scope compliance at multiple layers rather than trusting the agent to self-regulate. That said, the ROE document above is your responsibility before you hand any platform access to your systems. Governance doesn't start when the tool runs. It starts with defining what the tool is allowed to do.
One thing worth flagging explicitly: Astra’s platform currently focuses on web application & API testing. If your scope includes standalone API surfaces, it’s worth factoring that into your current tooling decisions and roadmap discussions with any vendor you evaluate.
Autonomous pentesting only augments them; the framing of "replacement" is worth retiring because it leads teams to make the wrong staffing and tooling decisions.
Here is what actually happens when autonomous pentesting is integrated into a security program. The mechanical, repeatable work that is possibly consuming a disproportionate share of your pentesters' time (running recon playbooks, scanning for known CVE patterns, validating basic exploit chains, generating finding reports in a consistent format) gets absorbed by agents.
What's left after agents absorb that layer is an understanding of your application's business logic sufficient to recognize when it's being abused, such as identifying attack chains that require creative sequencing across services, or threat modeling a new feature before it ships.
Where this gets complicated is governance. Organizations that treat autonomous tools as a headcount substitute rather than a capability multiplier tend to discover their mistake during an incident, usually one involving a business logic flaw or a novel attack chain that no agent flagged because no agent was capable of flagging it. That is a risk management decision made without full information.
It shifts the work, not the headcount requirement, at least not in any security program that's being run responsibly.
QA automation did reduce the number of people manually clicking through regression test scripts, but not those needed to write effective test strategies, design edge-case coverage, investigate flaky tests, and build the automation itself.
Autonomous pentesting absorbs the execution layer of repetitive testing, i.e., what it creates demand for is people who can configure agents intelligently, interpret complex findings, own the remediation workflow, and do the high-judgment work that agents surface but cannot resolve. Security programs that run autonomous tooling without humans to govern, interpret, and act on outputs are creating a very expensive false sense of security.
The headcount math that actually works: if you were previously running four pentests a year manually and autonomous tooling lets you run continuous testing across all your targets simultaneously, you now have more findings, more frequently, requiring faster triage and remediation than your existing team was built for, making this a workflow redesign scenario.
For larger organizations with many targets, autonomous pentesting removes the bandwidth bottleneck that previously made comprehensive coverage impossible. You're finally able to cover the attack surface you couldn't reach before.
Non-experts can start an AP, but interpreting the output safely and acting on it correctly still requires expertise, and platforms that obscure this in their marketing are setting customers up for trouble.
Most mature autonomous pentesting platforms, including Astra’s AP platform, have simplified the setup to the point where providing a target URL and login credentials is genuinely all you need to get started. For teams that already have a target configured on the platform, our setup takes just 2-3 clicks.
But after findings are reported, a non-expert looking at a critical finding involving a chained IDOR and a privilege escalation path needs to understand what the chain means, which link to break first, what the blast radius is if it's actively exploited before the fix ships, and how to communicate the urgency to an engineering team that's in the middle of a sprint. Those are judgment calls that require a security context.
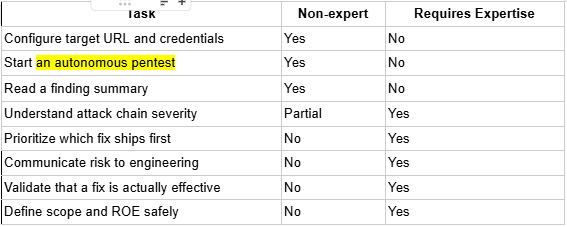
Where non-expert accessibility genuinely helps is in organizations where a founder or engineering lead needs to run an initial assessment before a dedicated security hire is in place, or where a product team wants continuous visibility without routing every question through an already stretched security team.
Astra Security's reports include chain-breaking guidance and prioritized remediation steps specifically because the platform is designed to reduce the interpretation burden on teams without deep security expertise.
An annual pentest tells you what was true about your application on the specific days testers examined it. Every endpoint that shipped after they left, every dependency update, every configuration change that drifted three weeks later, none of it gets caught until someone books another engagement. For teams shipping multiple times a week, that is a twelve-month blind spot dressed up as a security program.
Jan ──[ PENTEST]─────────────────────────────────────────────
Dec
↑ findings captured at a single point in time
↓
All changes, new code, and new vulnerabilities introduced here remain undetected until the next annual test cycle
Continuous testing closes that gap structurally. Every deploy triggers a fresh assessment. A new endpoint appears, and agents find it. Auth flow changes, agents test it. The time between a vulnerability being introduced and being found shrinks from months to hours — which is the metric that actually determines your exposure window.
Continuous autonomous testing model:
Jan─[SCAN]──[SCAN]──[SCAN]──[SCAN]──[SCAN]──[SCAN]─Dec
^ each deploy triggers a new assessment
findings surface within hours of introduction
The shift that teams consistently underestimate is what this requires from the rest of the organization. Annual pentests produce one report, triaged over a few weeks. Continuous testing produces findings on an ongoing basis, so your remediation workflow needs to be built for speed (rather than an annual sprint followed by 11 months of quiet).
Annual human engagements do not go away in this model. They get better. When agents have already handled the repeatable work continuously, the human pentesters you bring in annually can spend their entire engagement on business logic abuse, novel chaining, and the adversarial creativity that no agent surfaces. Your annual pentest becomes deeper, not redundant.
Astra's CI/CD integration is built specifically for this: a new autonomous pentest run is triggered directly from your deployment pipeline, so your security cadence finally matches your engineering cadence rather than running on a completely separate calendar.
The 80% cheaper claim holds up for standardized, repeatable assets tested frequently. It falls apart for complex applications with significant business logic, or anywhere a coverage gap creates an incident that the autonomous tool wasn't capable of preventing. A breach that traces back to a flaw the agent couldn't find is not a cost-saving; it is a deferred cost that has accrued interest.
The more honest ROI frame is this: continuous autonomous coverage plus one deeper annual human engagement costs meaningfully less than quarterly manual testing alone, while delivering more coverage, more frequently, with better use of human expertise where it actually matters.
For organizations with many targets, the argument sharpens further. Autonomous pentesting runs multiple targets in parallel without adding headcount — something structurally impossible with manual engagements. A team that could previously afford to test three targets annually can now run continuous coverage across all of them simultaneously. That is not a marginal efficiency gain.
Speed compounds this. When a vulnerability surfaces on a Monday morning instead of a Friday afternoon 2 weeks after an engagement closes, the fix ships faster, the exposure window is shorter, and the engineering cost of remediation is lower because the context is still fresh.
The ROI question, then, worth asking your vendor is "how much attack surface was I leaving uncovered before, and what does that exposure actually cost me?"
Yes, but with a condition that most vendors bury in their fine print: the platform has to be built for audit-grade evidence, not just scan output dressed up in a PDF.
For PCI DSS, a QSA will want to know exactly what was tested, how exploitation was confirmed, who reviewed the findings, and whether the scope covered all components of the cardholder data environment.
For ISO 27001, the focus is on whether your security testing is systematic, documented, and repeatable as part of a broader risk management program. For SOC 2, auditors want evidence that your vulnerability management process has teeth, i.e., findings are tracked, assigned, remediated, and verified.
What makes autonomous pentest output audit-ready is the substance behind each finding.
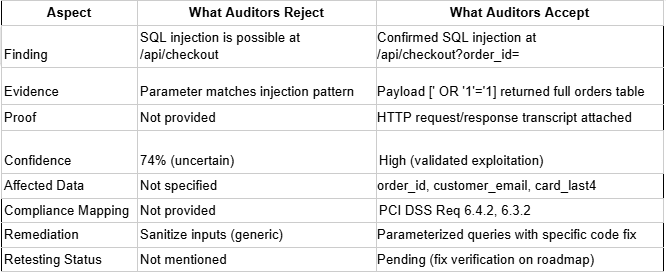
Astra's reports include proof of exploitation for every finding, attack chain context, severity tied to actual business impact, and direct compliance mappings to PCI DSS 4.0, ISO 27001, and other frameworks. The difference between an autonomous pentest report that satisfies an auditor and one that generates a follow-up questionnaire is whether the evidence shows what happened, not just what might happen.
Most compliance frameworks still expect at least annual human-led penetration testing as part of a complete program. Autonomous continuous testing meets the frequency and coverage requirements and supplements the annual scoped assessment. Any vendor suggesting otherwise is telling you what you want to hear.
PCI DSS 4.0 introduced two requirements that autonomous pentesting addresses well, and one it cannot fully satisfy on its own.
Requirement 6.4.2 mandates automated technical solutions in front of public-facing web applications to detect and prevent attacks. Continuous autonomous testing running against your application on every deploy satisfies this — and produces a documented evidence trail that demonstrates ongoing coverage rather than a once-a-year snapshot.
Requirement 6.3.2 requires a complete inventory of all custom software, including APIs and third-party components. Autonomous agents that crawl your application and map every endpoint, parameter, and service dependency generate exactly this inventory as a byproduct of normal operation. Most teams do not factor this into their ROI calculations, but they should.
Where autonomous testing alone falls short: Requirement 11.4 still mandates penetration testing by a qualified internal resource or third party, aligned to industry standards, at least annually and after significant infrastructure changes. An autonomous platform contributes to this requirement, but the annual assessment typically needs human sign-off to satisfy a QSA.
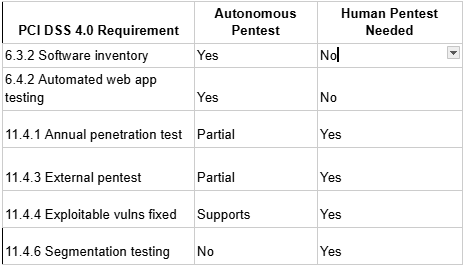
The practical setup that satisfies PCI 4.0 comprehensively includes continuous autonomous testing for ongoing coverage, inventory, and evidence generation, combined with an annual human-led engagement for the qualified assessment requirement. Astra covers both sides of this, i.e., autonomous pentesting for continuous coverage and PTaaS with certified human testers for the annual scoped assessment.
When an autonomous agent is running against your infrastructure at 2 am with no human watching, what stops it from going too far? Most vendors have an answer ready. OWASP APTS is how you verify whether that answer is actually true.
APTS (Autonomous Penetration Testing Standard) was built because every existing standard missed the same thing. PTES tells you what to test. NIST AI RMF talks about responsible AI in broad strokes. None of them addresses the specific problem of an AI system making real-time exploitation decisions on live systems, with no human in the loop, against infrastructure that serves real users.
That gap is not theoretical anymore. Autonomous pentesting tools are in production at scale in 2026. The question of how they govern themselves when something unexpected happens is a real operational risk, not a future concern.
APTS defines 173 requirements across 8 domains covering scope enforcement, safety mechanisms, auditability, and human override controls. It also gives you a concrete autonomy level framework to evaluate platforms against:

Before you give any platform credentials and a target, ask whether it aligns with APTS Tier 2 or Tier 3. Ask whether every agent's decision is auditable after the fact. Ask what the kill-switch looks like if the agent exceeds its defined scope. If the vendor needs time to look that up, you have your answer.
Astra's Co-Founder Shikhil Sharma and Pentest Lead Jinson Varghese Behanan helped write APTS. Which means the guardrails inside Astra's platform were not retrofitted to a standard after the fact. They were built alongside it. Scope enforcement, checkpointing, and override controls are structural decisions in the architecture, not configuration options buried in an admin panel.
The standard is open source at github.com/OWASP/APTS. Worth an hour before your next vendor evaluation.
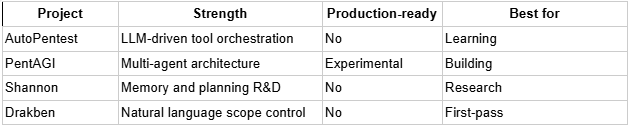
Open-source autonomous pentesting in 2026 is genuinely useful for learning, prototyping, and understanding where the hard problems are. Here is what the notable projects actually do:
AutoPentest (and tools in that category) chains established security tools like Nmap, Nikto, and SQLmap with an LLM orchestration layer for recon and basic vulnerability identification. Good for understanding how LLMs handle tool-calling loops. Struggles with complex multi-stage exploitation and authenticated flows, so keep it in lab environments.
PentAGI has a more formal multi-agent architecture with explicit state management and planning. The emphasis on observability and execution monitoring makes it a useful reference for what good agentic architecture looks like, internally more structured than automation scripts, less complete than production tooling.
Shannon sits squarely on the research frontier, focused on the memory and planning problems that trip up most current agents. It directly addresses how agents maintain context across long-running, multi-step attack chains, which is exactly the gap between simple tool chaining and genuine penetration-testing reasoning.
Drakben uses natural language to define scope and constrain agent behavior. The most accessible of the group, and a practical starting point for technical leads or founders who need a first-pass assessment without deep security expertise on staff yet.
Three things worth keeping in mind across all of them. First, there is a meaningful difference between tools like PentestGPT (which assists human testers by reducing cognitive overhead) and genuinely autonomous projects like PentAGI. The label "autonomous" gets applied loosely.
Second, treat any finding from open-source agents as an unverified indicator until manually confirmed, meaning reproducible proof-of-exploit is rare across these projects.
Lastly, the field is moving toward human-in-the-loop architectures, where agents suggest attack paths, and humans validate the next step. Prioritize projects with clear execution logs and pause/resume functionality if you are evaluating for internal use.
Commercial platforms like Astra Security build on these foundations but add what actually matters for security programs: validated findings with proof of exploitation, compliance-mapped reporting, and governance architecture that holds up when someone asks what the system did and why. That layer does not yet exist in open-source implementations.
Yes, but not as much as the architecture around it. The LLM handles reasoning: interpreting tool outputs, planning the next probe, deciding whether a response indicates a vulnerability or a dead end. Better reasoning models produce fewer hallucinated findings and handle ambiguous responses more gracefully, particularly in complex multi-step scenarios where the agent needs to hold context across a long chain of actions.
But the model is only one variable. An excellent model inside a poorly designed agent framework will still hallucinate its way into garbage findings, but a well-constrained framework with explicit state management, retry budgets, and a separate validation layer will produce more reliable output than a raw GPT-4o call with no guardrails, regardless of how capable the underlying model is.
python
# Two agents, same model, completely different reliability:
# Agent A: raw LLM call, no validation
response = llm.complete(f"Test {endpoint} for SQL injection")
finding = parse_response(response)
report.add(finding) # No verification — hallucinates freely
# Agent B: constrained framework with validation
probe_result = tool_runner.execute(sqli_probe, endpoint)
if probe_result.has_evidence():
validation = validator_agent.confirm(probe_result)
if validation.exploited:
report.add(validated_finding) # Only confirmed exploits surface
What practitioners in r/netsec build threads consistently find: model upgrades help at the margins in complex scenarios. Better state management and tool constraints make the bigger reliability difference across the board.
Astra's approach runs two separate AI layers: one army of agents finds vulnerabilities, while a dedicated validator AI confirms them by actually completing the exploit. This separation is what drives findings toward near-zero noise rather than relying on a single model to both find and verify its own work.
The practical implication when evaluating platforms: ask about the validation architecture, not the model. "We use GPT-4o" is a marketing statement. "Here is how we confirm a finding before it reaches your report" is an engineering answer.
Most evaluation conversations start with the wrong questions. "How many vulnerabilities did you find in our demo?" is not a useful signal. A tool that finds 300 unvalidated findings looks more impressive than one that finds 40 confirmed exploits, until you spend three weeks triaging the 300 and discover that 11 of them were real.
Here are the questions that separate platforms worth evaluating from ones worth skipping:
Does it prove exploitation or just flag it? Ask to see an actual finding output, not a sanitized demo screenshot. The finding should include the exact payload, the response that confirmed exploitation, and reproducible steps. If the evidence section says "confidence: 87%" instead of showing you what happened, that is a scanner with a better interface.
How does it handle scope enforcement? Ask specifically: what happens if an agent encounters a link that goes outside the defined target? What prevents it from following that link? If the answer involves the agent "making a judgment call," ask for the architectural answer instead.
What does the validation layer look like? Is there a separate confirmation step, or does the same agent that finds a vulnerability also declare it valid? Self-validation is a structural conflict of interest in agent design.
Can it integrate into how your team actually works? CI/CD trigger on deploy, findings pushed to Jira, report format your engineering team will read rather than file. A platform that produces a PDF you email to developers once a month is not a security program. It is a document.
What is honestly out of scope? Any platform that claims full coverage of business logic, zero-days, and complex cross-service chains is overselling. Ask directly what the tool cannot find, and evaluate whether those gaps are acceptable given your risk profile.
Does it align with OWASP APTS? Ask specifically which APTS compliance tier the platform targets and how scope enforcement and human override controls are implemented. A vendor that has not heard of APTS in 2026 is a signal worth noting.

Astra checks the boxes that matter: proof of exploitation on every finding, structural scope enforcement with multi-layer checkpointing, a separate validator AI, CI/CD, and Jira integration from day one, and honest roadmap communication on what is not available yet (fix verification and cross-target testing are coming, and the team will tell you that directly rather than implying they exist).
What Astra does not do that some platforms claim: cross-target attack chains spanning multiple applications in a single scope (on the roadmap), cloud infrastructure testing (also on the roadmap), and fix verification autonomous pentests (coming soon).
If those are non-negotiables for your current evaluation, factor them in. If you are evaluating for web application coverage with genuine depth, breadth, and audit-grade evidence, that is where Astra Security Autonomous Pentesting was built to compete.
The integration pattern that often works triggers a scoped autonomous test on merge to main, runs it against your staging environment, pushes findings to your ticketing system, and lets your security team triage asynchronously rather than blocking the pipeline on pentest results.
Blocking deploys on pentest output sound good in a security meeting, but cause chaos in practice. A false positive on a Friday afternoon should not hold up a release. The right gate is: critical confirmed findings from production surfaces trigger an alert and a human decision. Everything else flows into the remediation backlog with appropriate severity tagging.
yaml
# GitHub Actions example — autonomous pentest on deploy
name: Autonomous Security Test
on:
push:
branches: [main]
jobs:
pentest:
runs-on: ubuntu-latest
steps:
- name: Trigger Astra Autonomous Pentest
uses: astra-security/pentest-action@v2
with:
target_url: ${{ secrets.STAGING_URL }}
credentials: ${{ secrets.TEST_USER_CREDS }}
scope: web-application
notify_on: critical, high
- name: Push findings to Jira
if: failure()
uses: astra-security/jira-integration@v1
with:
project: SEC
severity_threshold: medium
Astra supports CI/CD integration from day one alongside GitHub and Jira. Findings route directly into your existing workflow rather than sitting in a separate security portal your engineering team never opens.
The tool surfaces the finding. Everything after that is a governance problem, and most teams underinvest in solving it before the first AP runs.
The setup that works: findings route to the engineering owner of the affected service, not to a generic security inbox. SLAs are defined by severity before the first AP, not negotiated finding by finding. Re-testing is scheduled as part of the fix definition, not treated as an optional follow-up.
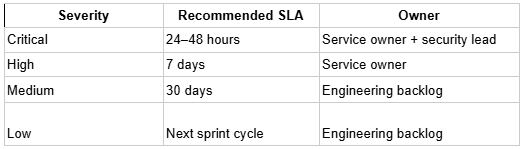
The failure mode that shows up consistently, findings are added in Jira, get triaged once, and then age in the backlog while the attack surface they represent stays open. Autonomous testing that runs continuously makes this worse, not better, if the remediation workflow is not built for sustained throughput.
Astra's Jira integration pushes findings with severity, affected assets, chain context, and fix guidance attached. The finding arrives with everything the engineer needs to act on, rather than requiring back-and-forth with the security team to understand what to do.
Fix verification via re-running the AP, which is on Astra's AP roadmap. Until it ships, running a fresh autonomous test after significant fixes is the practical alternative.
The near-term developments worth watching across the industry include better multi-step attack chain reasoning, cross-service scope that lets agents chain findings across multiple targets, and fix verification that closes the loop between finding and confirmed remediation.
For Astra AP specifically, here is what is coming without committing to specific timelines:

The failure mode that shows up consistently, findings are added in Jira, get triaged once, and then age in the backlog while the attack surface they represent stays open. Autonomous testing that runs continuously makes this worse, not better, if the remediation workflow is not built for sustained throughput.
Astra's Jira integration pushes findings with severity, affected assets, chain context, and fix guidance attached. The finding arrives with everything the engineer needs to act on, rather than requiring back-and-forth with the security team to understand what to do.
Fix verification via re-running the AP, which is on Astra's AP roadmap. Until it ships, running a fresh autonomous test after significant fixes is the practical alternative.