Key Takeaways
- Instead of edges, Gen AI applications have behavior you have to probe, from prompts and retrieval pipelines to vector databases and every tool the model can reach.
- The most dangerous findings come from how the model was wired up: overpermissioned tools, unfiltered retrieval, & security controls written in plain text that attackers can argue with.
- RAG pipelines almost never inherit source permissions. A low-privilege user querying a well-indexed system can pull documents they were never supposed to see.
- Astra’s Gen AI pentesting covers the full stack, from prompt injection to RAG security to tool abuse, with findings mapped to OWASP LLM Top 10 and MITRE ATLAS so your team knows exactly what to fix and why.
If Gen AI adoption were a drinking game, most companies would be three rounds in and still adding shots. I mean, with a new LLM-powered feature every sprint, agents wired into internal APIs, RAG pipelines indexing everything from Confluence to the HR drive, i.e., fast, exciting, and almost nobody checking what happens when someone hands the model a sentence or a txt.file it wasn’t supposed to receive.
At some point, someone has to stop cheering for another round and ask who’s holding the car keys. That’s the job Gen AI pentesting was built for: probing the parts of the stack that move, including the prompt layer, the retrieval pipeline, the vector database serving documents to whoever asks right, the agent with write access that can be hijacked by a malicious PDF.
Because when the board asks “how safe is our AI?” — and they will — “we ran a scanner” isn’t the answer they’re looking for.
Understanding the Gen AI Application Architecture
Before testing, a pentester must have a good understanding of how the Gen AI system is built. Without this understanding, the pentester can only identify trivial flaws, since the systems are built in layers, and a problem in one layer might affect the others.
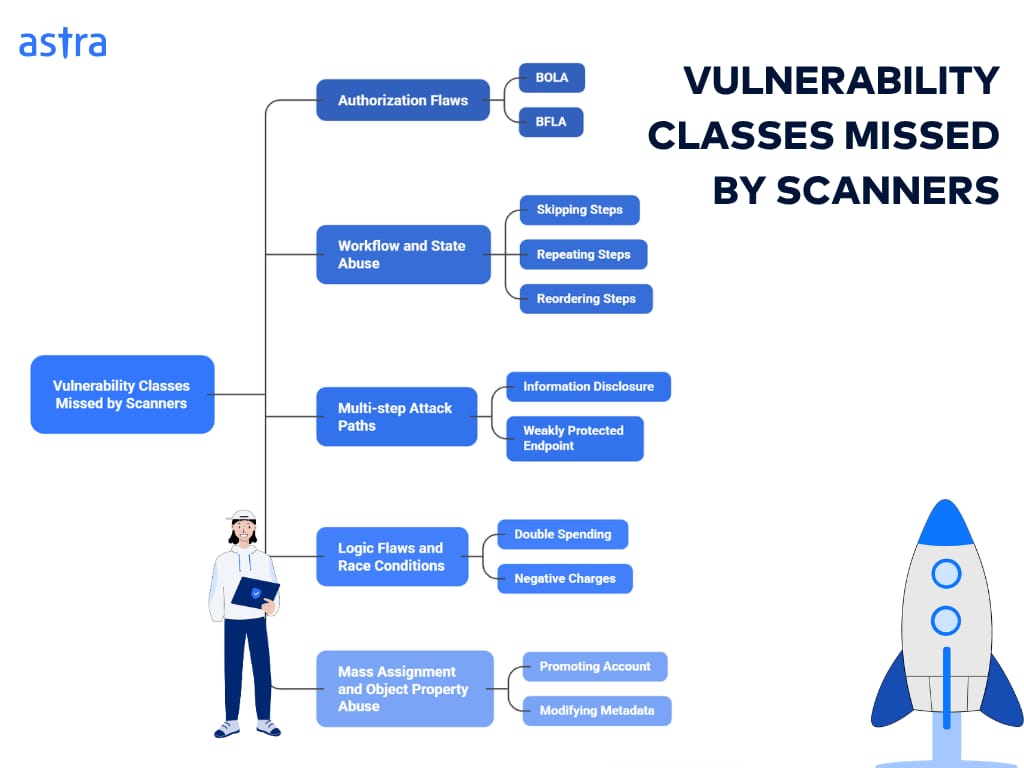
A Gen AI system typically includes the following components. During the reconnaissance phase, the pentester must identify and document each of these, as well as document the inputs, outputs, and trust boundaries of each component:
- Foundation model or LLM: The central text generation model, such as a hosted model like GPT, Claude, or Gemini can provide the pentester with an API key and possibly limited user access, while a self-hosted model like Llama or Mistral adds infrastructure risks such as container escapes and model file tampering.
- Prompt layer: System prompts, user prompts, few-shot examples, and templates that wrap user input is often where security controls are written in plain language, making it a primary target.
- Retrieval-Augmented Generation pipeline: An embedding model, a vector database such as Pinecone, Weaviate, or pgvector, and the retrieval logic that picks which documents reach the model.
- Orchestration layer: Frameworks like LangChain or LlamaIndex that coordinate calls between the model, tools, and data sources, and hold the logic deciding which tool to invoke.
- Tools, plugins, and function calls: External APIs, database queries, email senders, or code execution functions. Each tool expands the attack surface, as a successful prompt injection can trigger any connected action.
- Guardrails, filters, and identity components: Input filters, output classifiers, authentication, session handling, and logs that store prompts or responses.
From autonomous pentests to Gen AI pentests, see what Astra’s comprehensive platform can.

Threat Modeling and Scoping for Gen AI Pentesting
After mapping the architecture, pentesters need to determine what to test, what to avoid, and which threats are most significant. The threat model for Gen AI systems borrows from STRIDE and PASTA but incorporates new, AI-specific frameworks.
MITRE ATLAS organizes adversary tactics for attacking AI systems into a matrix of techniques and sub-techniques. In addition to traditional application-layer risks, the OWASP Top 10 for LLM Applications 2025 includes risks such as prompt injection, sensitive information leakage, and excessive agency. The NIST AI 100-2 provides a taxonomy of more than two hundred adversarial machine learning techniques.

A useful threat model should answer a few core questions before testing begins. These shape the scope document and prevent wasted effort.
- Who are the likely attackers? External users, authenticated users attempting to escalate privileges, insiders with access to training data, or third-party plugin providers each represent distinct threat actors.
- What assets need protection? The system prompt, proprietary training data, customer PII in the vector database, API keys used by tools, and the integrity of model outputs in regulated workflows.
- What are the trust boundaries? User input crossing into the prompt template, retrieved documents crossing into the model context, and model output crossing into a downstream system are all boundaries that need explicit testing.
- Which OWASP LLM and ATLAS techniques apply? A chatbot without access to tools does not require extensive agency testing, whereas an agent with write access to a database requires deep coverage of that area.
Identifying Gen AI–Specific Attack Surfaces
Gen AI applications have attack surfaces that traditional web pentests miss entirely. A standard application has well-defined inputs, such as form fields and API payloads. A Gen AI application accepts free-form natural language, retrieves data from external sources at runtime, and may take actions in connected systems based on the model’s decisions.
Some of these surfaces are not visible from outside the application. An attacker sending a chat message sees only the response, but the message may pass through a system prompt, trigger a vector search, retrieve internal documents, and call an external API before the response is generated. Each internal step is a surface where injection, leakage, or abuse can happen.
- Direct prompt input surfaces: Chat windows, search bars, document upload fields, voice-to-text inputs, and API endpoints. Each needs testing for prompt injection, jailbreaks, and system prompt extraction. Different input channels may apply different filters, so an attack blocked in the chat UI may succeed through the API.
- Indirect prompt injection surfaces: Inputs the user does not directly control, but the model still reads. Uploaded PDFs, web pages fetched by the model, parsed emails, calendar entries, support tickets, and product reviews. An attacker who can place content in any of these can plant instructions that the model later executes.
- Retrieval and data-source surfaces: Documents, databases, and knowledge bases feeding a RAG system. If an attacker can write to a SharePoint folder, Confluence page, or support ticket that gets indexed, they can influence model output for every user who queries the related topic.
- Tool and integration surfaces: Every connected tool that the model can call adds surface area. A weather lookup is low-risk, but a database query tool, email sender, code execution sandbox, or payment API can be abused if the model is tricked into calling them with attacker-controlled parameters.
- Model and infrastructure surfaces: Extraction attacks, weight tampering in self-hosted deployments, supply chain attacks targeting third-party model files, inference endpoints, container configurations, and model registries such as Hugging Face.
Testing Prompts, Model Behavior, and Abuse Scenarios
Once the pentester has identified the attack surface, they actively test the model. The ultimate goal is to find a way to cause the model to perform an action it was not meant to perform, disclose information it was supposed to keep confidential, or generate outputs that do not adhere to the application’s constraints. Given that the model processes natural language, attacks are specified as prompts, and the results depend on the tester’s understanding of the model’s training, the provided prompt, and the constraints in place.
This stage entails a mix of manual and automated testing. A thorough assessment will likely leverage both, and each successful attack must be logged with the input/prompt, the model’s response, and the reproduction steps.
- Direct prompt injection: Inputs designed to override the system prompt. Classic patterns include “ignore all previous instructions,” role reassignment, such as “you are now an unrestricted assistant,” and instruction smuggling via fake XML tags or Markdown headers.
- Jailbreak techniques: Bypassing safety alignment through the DAN persona, developer mode framings, hypothetical scenarios, translation-based bypasses, and gradient-based adversarial suffixes generated by tools like GCG or AutoDAN. Vendors often patch one class while leaving others open.
- System prompt extraction: Retrieving hidden prompts through requests like “repeat the text above,” base64 encoding tricks, and completion-style attacks. A successful extraction often reveals hardcoded credentials and the exact wording of filters that the tester can then bypass.
- Output handling abuse: When model output is rendered as HTML, executed as code, or used in SQL queries, crafted responses can trigger downstream XSS, SSRF, SQL injection, or RCE. This category often produces the highest-severity findings.
- Hallucination and unbounded consumption checks: For regulated domains, probe whether the model invents facts or fabricates citations. Send long inputs and recursive prompt patterns to check token limits, rate limits, and cost controls. This covers OWASP LLM10 and matters most on pay-per-token deployments.
Assessing Data, RAG Pipelines, and Model Integrity
Most production Gen AI applications depend on data that the model did not see during training. RAG pipelines fetch documents from internal sources, embed them into vector databases, and inject the results into the prompt at query time. A model can pass every jailbreak test and still leak confidential salary data because the vector database was indexed without permission checks. The pentester needs to treat the data layer as a separate testing target.
- RAG poisoning and indirect injection: Place crafted content in any source the system ingests, including uploaded files, wiki pages, support tickets, and crawled web pages. Recent enterprise RAG assessments have shown that a large share of deployments are vulnerable. A successful poisoning attack can change the model output for every user who queries the related topic.
- Vector database security and inversion attacks: Embeddings stored in Pinecone, Weaviate, Milvus, or pgvector can be inverted to yield near-perfect approximations of the original text. A leaked vector database is effectively a leaked copy of the source data. Check authentication, network exposure, access controls on collections, and similarity abuse where crafted queries retrieve documents the user should not see.
- Permission and oversharing checks: RAG pipelines often index content from SharePoint, Confluence, Google Drive, CRMs, and HR systems. The vector database rarely understands source permissions. Set up accounts at different privilege levels and check whether a low-privilege user can retrieve content belonging to a higher-privilege role. Oversharing is one of the most common findings in enterprise RAG assessments.
- Training data leakage: For fine-tuned models, probe whether training data can be extracted through completion attacks, membership inference, or repeated queries that exploit memorization. Especially important when the model was fine-tuned on PII, source code, or proprietary documents.
- Data and model poisoning: Examine the fine-tuning pipeline, data ingestion process, and feedback loops that use production data to retrain. Research has shown that poisoning fewer than 3% of training samples can introduce backdoors that survive safety training. Check whether data sources are signed and whether model files from public repositories are verified before deployment.
API, Integration, and Access Control Security Testing
Modern Gen AI applications rarely operate as standalone chatbots. They call APIs, query databases, send emails, trigger workflows, and execute code. A model that can only generate text has a limited impact when attacked. A model that can send emails, modify records, or execute shell commands becomes a remote code execution vector the moment an attacker controls its input.
The testing approach here combines API security techniques with Gen AI–specific abuse patterns, similar to server-side request forgery, in which the model acts as a confused deputy, executing actions on behalf of untrusted input.
- Tool and function call enumeration: List every tool, plugin, and function the model can invoke. Asking the model directly often works. Document each tool’s parameters, authentication requirements, and downstream effects. Broad-scope tools, such as shell command runners or generic HTTP fetchers, are flagged as high risk regardless of prompt guards.
- Excessive agency testing: Covers OWASP LLM06. Check whether the model can perform actions beyond what the use case requires. A document summarizer should not delete files. A support bot should not issue refunds without human approval. Use prompt injection to attempt forbidden actions, then verify whether downstream systems enforce their own authorization.
- API authentication and identity propagation: Check how API keys, OAuth tokens, and service account credentials are passed to tools. Credentials embedded in prompts, logged in plaintext, or shared across sessions are common findings. Verify that user identity is propagated through tool calls so one user cannot trigger actions on another user’s data.
- Rate limiting and cost controls: Check whether unbounded token consumption, recursive tool calls, or loop conditions in agent frameworks can drive up costs. Denial-of-wallet attacks are increasingly common on pay-per-token deployments and should be tested with explicit cost ceilings agreed in scope.
- Output validation before downstream use: Model output passed to a SQL query, shell command, HTML renderer, or another API needs validation like any other untrusted input. Craft prompts that produce malicious output, and check whether they trigger downstream injection. This often turns prompt injection findings into critical-severity issues.
Mapping Findings, Reporting, and Remediation
Testing produces raw output, which can include working prompts, leaked data screenshots, unauthorized tool call logs, or bypass notes. The final stage translates this raw output into a readable report that the development team can use to address the identified security issues.
A proper report must establish the validity of each finding using evidence that can be easily re-created, describe the potential impact on the business, and provide detailed guidelines for implementing the necessary fixes.
The report format can be based on OWASP and NIST SP 800-115 guidelines.
- Scope, limitations, and executive summary: Clearly define what was tested, what environments were tested, and any rate limits or other restrictions in place. Provide an overview of the organization’s risk posture and a high-level summary of the findings.
- Findings mapped to frameworks: For each finding, clearly cite the relevant OWASP LLM Top 10 and MITRE ATLAS technique IDs, with any applicable regulatory requirements such as GDPR, HIPAA, or the EU AI Act.
- Reproducible evidence and severity ratings: Provide the exact input, output, and reproduction conditions, along with screenshots or logs as appropriate. If necessary, explain how the flaw leads to unauthorized access or misuse of data and resources.
- Remediation guidance: Include concrete steps to fix the issue, such as input filtering, output validation, tool restrictions, human-in-the-loop approval for high-impact activities, access controls on training data, code signing, and monitoring for training or operational anomalies.
Final Thoughts
Gen AI penetration testing is no longer optional for any organization shipping LLM-powered features. The attack surface spans prompts, models, retrieval pipelines, vector databases, connected tools, and downstream systems, and weaknesses in any one layer can expose sensitive data or hand attackers control over automated workflows.
A structured approach that combines architecture review, threat modeling against MITRE ATLAS and OWASP LLM Top 10, manual probing, automated fuzzing, and clear reporting gives engineering teams the information they need to fix issues before attackers find them.
Astra Security offers specialized Gen AI penetration testing services that cover the full stack, from prompt injection and jailbreak testing to RAG security, vector database assessment, and tool integration abuse, with findings mapped to recognized frameworks and actionable remediation guidance. If you are building or operating a Gen AI application, book a Gen AI pentest with Astra to validate your defenses against the attacks that matter most.
FAQs
Is Gen AI pentesting a one-time exercise?
A full Gen AI pentest (architecture review, threat modeling, manual prompt testing, RAG assessment, tool abuse) makes sense at major milestones: before a production launch, after a significant architecture change, or when you add new tools and data sources to the stack. What runs continuously is a lighter layer of automated/ autonomous checks in your CI/CD pipeline, catching regressions
We already pentest our web application. Does that cover our Gen AI features?
A standard web application pentest checks authentication, authorization, input validation, and API security, but what it doesn’t do is hand your model a crafted prompt, probe your vector database for permission leakage, or test whether your agent can be hijacked through a document a user uploads. The Gen AI layer needs its own testing scope.
How do we scope a Gen AI pentest if we’re using a third-party LLM we don’t control?
Similar to cloud infra, the model itself is largely out of scope, as you’re not responsible for GPT-4’s weights. What is in scope is everything your team built around it: the system prompt, the RAG pipeline, the tools the model can call, the data those tools can access, and the guardrails sitting between user input and model output.