With the rapid integration of machine learning technologies into various industries, the possibility of malicious attacks targeting them through vulnerabilities has grown. Machine Learning models are powerful yet prone to severe vulnerabilities due to data dependency and lack of standardized security measures.
This rise in threats has prompted OWASP to release a list of vulnerabilities that would affect these models and the steps taken to mitigate them.
The OWASP Top 10 for Machine Learning Includes:
- Input Manipulation Attack
- Data Poisoning Attack
- Model Inversion Attack
- Membership Inference Attack
- Model Theft
- AI Supply Chain Attacks
- Transfer Learning Attack
- Model Skewing
- Output Integrity Attack
- Model Poisoning
What is The OWASP Machine Learning Top 10?
The OWASP Machine Learning Security Top 10 is a comprehensive guide developed by the OWASP foundation to address severe vulnerabilities in machine learning models and systems. Organizations can protect their ML systems against attacks that occur in the various stages of the ML lifecycle to ensure robust and reliable ML applications.
With the emergence of AI since OpenAIs GPT launch, OWASP accelerated its research on potential vulnerabilities in machine learning and LLMs. Ananda Krishna, CTO of Astra Security, has contributed to the machine learning top 10 list.

OWASP Machine Learning Security Top 10 Explained with Examples
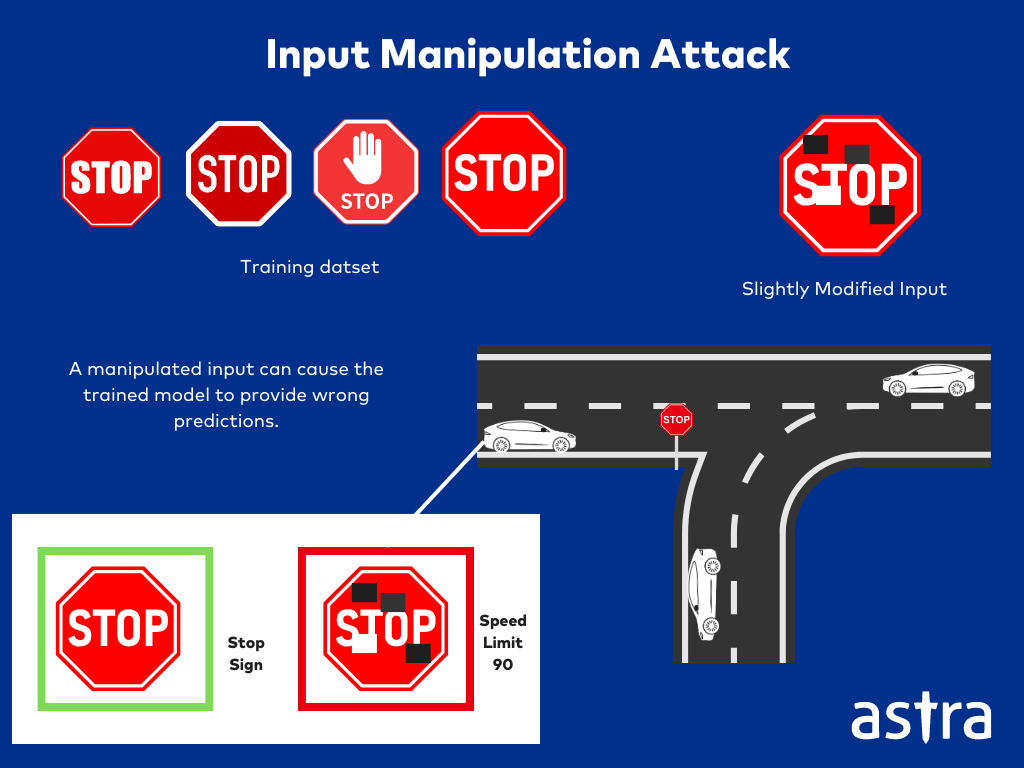
ML01-2023: Input Manipulation Attack
Input Manipulations are those in which attackers alter the input data to misdirect the machine learning model. These also include Adversarial attacks in which even slight and deliberate modification of the data can cause severe errors in the model predictions.
Example Attack Scenario for Input Manipulation Attack
Input Manipulation in Image Classification Systems.
Let’s say a deep learning model is trained to classify images into various categories of dogs and cats. An attacker can alter or modify a few pixels of an image of a cat, appearing to be the original. Such small changes can easily cause the model to misclassify the image incorrectly as a dog. This can cause the manipulated image to bypass security measures or harm the system.
ℹ️ In 2023, researchers experimented with placing stickers on road signs to mislead the Tesla’s autopilot system. It caused the cars to misinterpret stop signs as speed limit signs, leading to incorrect model behavior.
ML02-2023: Data Poisoning Attack
Data Poisoning attacks occur when the attackers inject malicious data into the training data set, corrupting the learning phase of the model and leading to incorrect model behavior and predictions.
Example Attack Scenario for Data Poisoning Attack
Training a Network Traffic Classification System
The training data for the network traffic classification system in the machine learning model is poisoned through incorrect labeling of various types of traffic. As a result, the model misallocates network traffic to the wrong categories or network resources.
ℹ️ In 2022, a negative comment detector on Google’s Perspective API was targeted with a data poisoning attack. Attackers injected malicious data during the training phase, causing the model to misclassify toxic comments as non-toxic and vice versa.
ML03-2023: Model Inversion Attack
Model Inversion Attacks occur when attackers reverse-engineer the model to reveal sensitive information from its output. Two possible ways such an attack can be executed are by stealing personal information and bypassing a bot detection model.
Example Attack Scenario for Model Inversion Attack
Stealing Personal Information
Attackers can train a facial recognition model and use it to invert the predictions of another face recognition model. This is done by exploiting vulnerabilities within the model implementation or API, with which the attacker can recover personal information used during the training phase.
ℹ️ In 2023, researchers performed a model inversion attack on a commercial facial recognition system to reconstruct images of individuals’ faces by querying the model with various inputs. This attack exposed sensitive information in the training data.
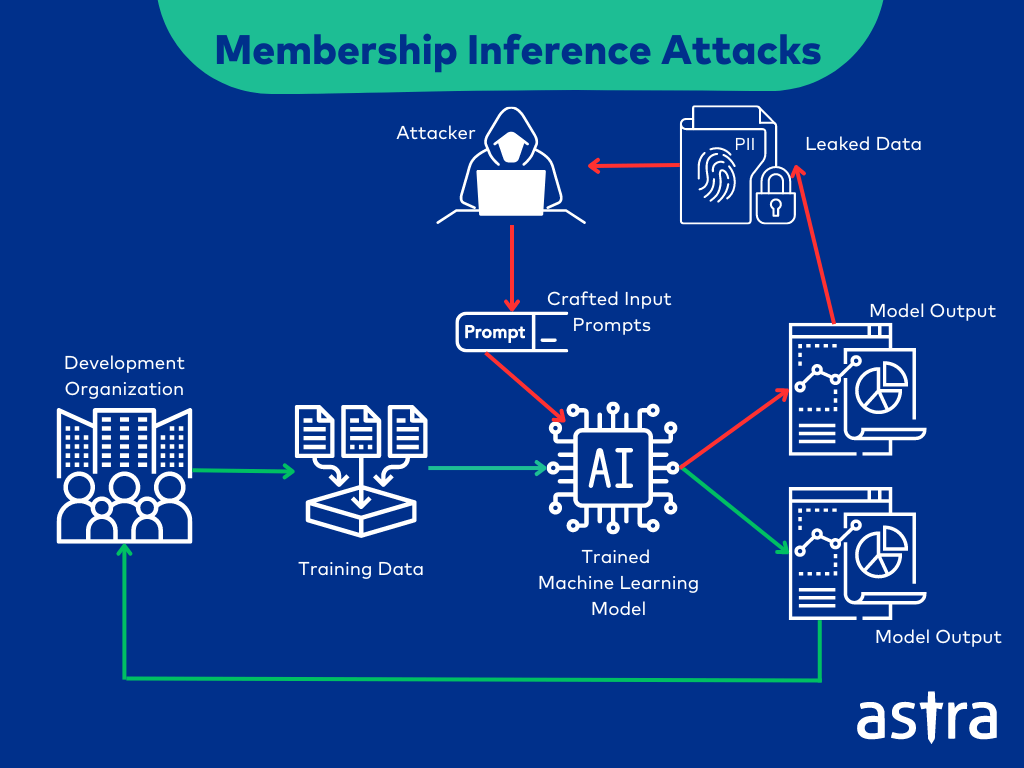
ML04-2023: Membership Inference Attack
Membership Inference Attacks occur when the attacker manipulates the training data used for the machine-learning model to expose sensitive data. This attack is carried out if the ML system does not have proper access controls, data encryption, or backup and recovery techniques.
Sensitive information about the dataset can be inferred, leading to privacy breaches.
Example Attack Scenario for Membership Inference Attack
ML Model Used to Extract Financial Data
Attackers use membership inference to query whether a particular individual’s financial data was used to train a financial prediction model. Attackers can use this to extract sensitive private and financial information about the individuals.
ℹ️ In 2023, attackers used a machine-learning model trained on financial records to determine if specific people were part of the training data and extract their sensitive financial information.
ML05-2023: Model Theft
Model Theft or Model Extraction is an attack in which an attacker tries to replicate an ML model by repeatedly querying it, using the outputs to recreate the model, and gaining access to its parameters.
Example Attack Scenario for Model Theft
Steal an ML Model From a Competitor
Attackers execute this attack by either reverse engineering the model by decompiling the binary code or repeatedly querying it to gain access to its parameters. Once they have access to the model’s parameters, attackers can start using it for themselves, causing financial and reputational damage to the competitor.
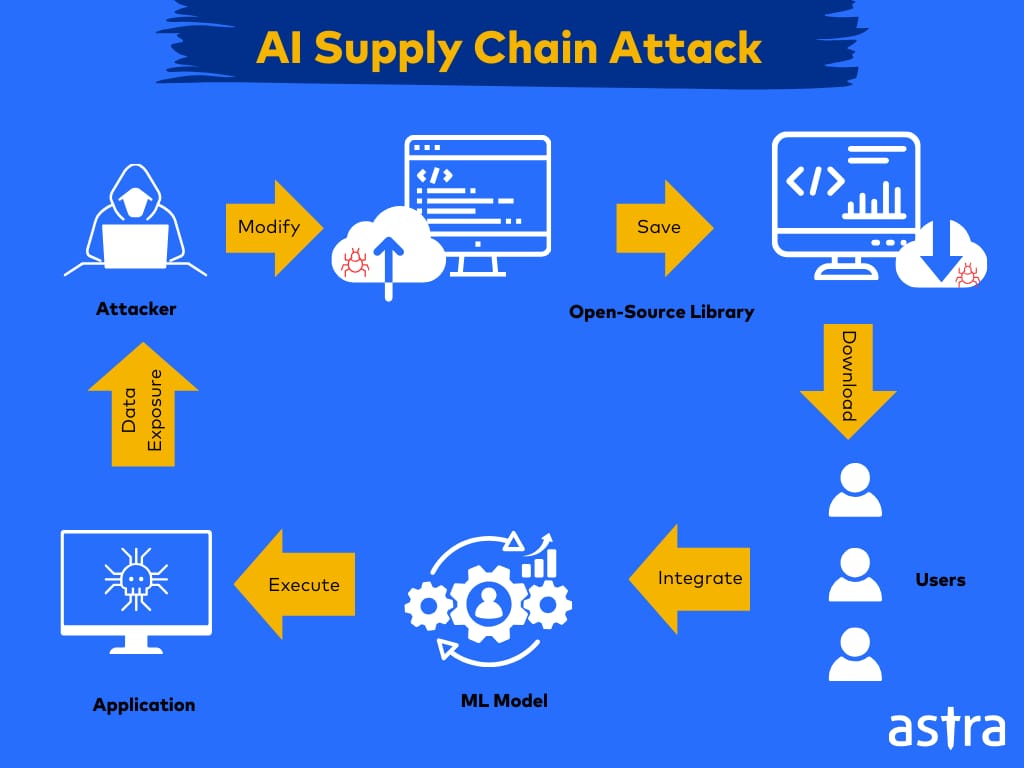
ML06-2023: AI Supply Chain Attack
AI Supply Chain Attacks or Corrupted packages occur when an attacker modifies or replaces an ML library or model the system uses.
This usually occurs due to reliance on untrustworthy third-party code or heavy reliance on open-source packages that can be modified to affect the system upon downloading.
Example Attack Scenario for AI Supply Chain Attack
Attack on an Organization’s ML Models
If an organization uses a public library in its applications, attackers can replace or modify the library’s code. When the target organization uses the compromised library, attackers can execute malicious activities within the organization’s ML applications.
ℹ️ In 2022, an AI supply chain attack targeted an open-source machine learning library. Malicious code was injected into the library, which, when downloaded by users, allowed the execution of malicious actions.
ML07-2023: Transfer Learning Attack
Transfer Learning attacks exploit vulnerabilities in pre-trained models, fine-tuning them and training them for another task, introducing weaknesses in the new model that lead to malicious model behavior.
Example Attack Scenario for Transfer Learning Attack
Using Malicious Dataset to Train a Medical Diagnostics Model
Attackers can train a dataset with manipulated images to target a Medical Diagnosis system. Once it starts using the tampered dataset, the system can make incorrect predictions, leading to incorrect diagnoses and harmful treatment suggestions.
ℹ️ In 2022, attackers exploited transfer learning by poisoning a pre-trained model, and when it was fine-tuned for malware classification, it misclassified malware samples as benign.
ML08-2023: Model Skewing
Model Skewing attacks occur when an attacker manipulates the training data distribution to cause undesirable behavior in the models, affecting the accuracy of the predictions.
Example Attack Scenario for Model Skewing
Targeted Product Suggestions Through Model Skewing
Attackers skew the feedback data for a product suggestion model’s predictions, leading to biased product suggestions for users.
ℹ️ In 2023, a model skewing attack was conducted on a credit scoring model used by a financial institution. Attackers manipulated the feedback data, causing the model to classify high-risk individuals as low-risk incorrectly.
ML09-2023: Output Integrity Attack
Output Integrity Attacks are those in which the attackers modify or manipulate the output of an ML model, which leads to incorrect or altered results being presented to the users or the systems being used.
Example Attack Scenarios for Output Integrity Attack
Modification of Fraud Detection System
Output Integrity Attacks are those in which the attackers modify or manipulate the output of an ML model, which leads to incorrect or altered results being presented to the users or the systems being used.
ℹ️ In 2023, an output integrity attack targeted a healthcare diagnosis system. Attackers altered the model’s outputs, leading to incorrect medical diagnoses.
ML10-2023: Model Poisoning
Model Poisoning attacks occur when the attacker manipulates the mode’s parameters to degrade its behavior, affecting the performance or introducing specific biases.
Example Attack Scenarios for Model Poisoning
Model Poisoning a Sentiment Analysis Model
Attackers can input poisoned data during the training phase of the ML model, causing a sentiment analysis model to misinterpret positive sentiments as negative. They can lead to harmful automated responses for business emails.
How To Prevent OWASP Machine Learning Top 10?
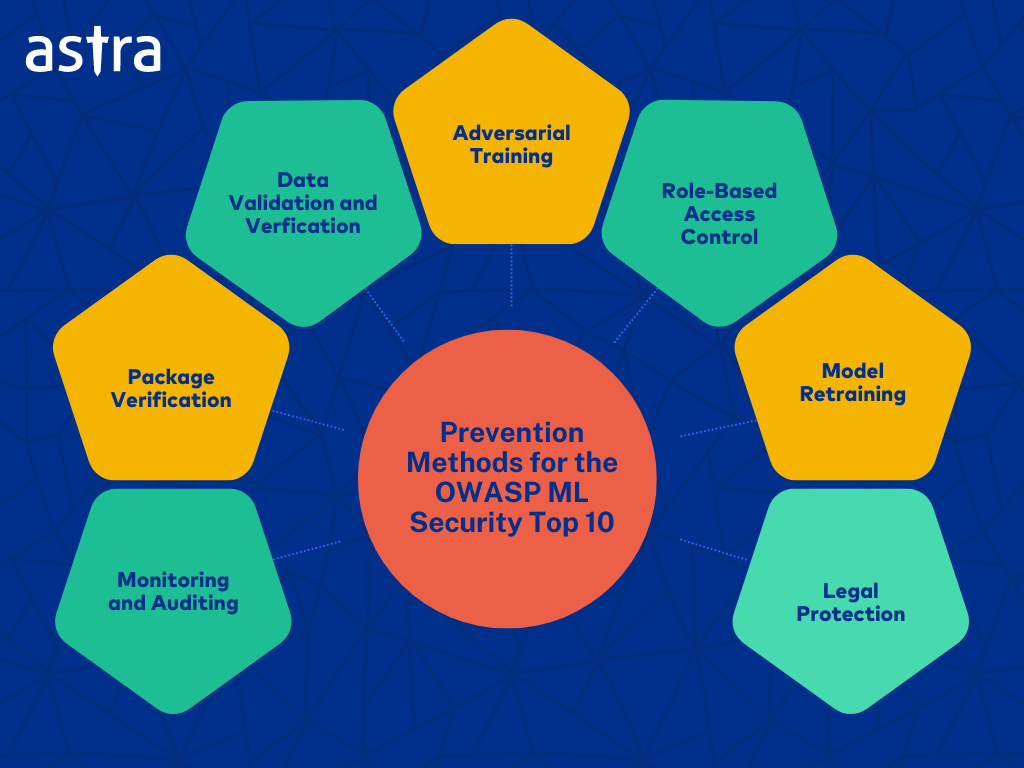
- Adversarial Training: Train models on adversarial examples to improve robustness against manipulation attacks and provide adversarial model training to reduce the chances of being successfully attacked.
- Data Validation and Verification: Data validation checks and multiple data labelers should be employed to ensure the accuracy of the labeled data. Data validation can be subcategorized into input validation and model validation.
- Access Control: Implement a strict role-based access control mechanism to limit who can interact with the model and avoid the unauthorized processing of the training data.
- Model Retraining: the machine learning model is regularly retrained to ensure that the system remains up to date, thus reducing the chances of information leakage from model inversion.
- Monitoring and Auditing: Monitoring and auditing the data regularly and at specific intervals can help detect anomalies and data tampering. Models should also be tested regularly for abnormalities to prevent attacks such as inference attacks.
- Package Verification: Verify the integrity of third-party libraries and tools used in the ML pipeline.
- Legal Protection: Ensure that the ML model is adequately protected in terms of legality with respect to patents and trade secrets. This will make it difficult for attackers to steal or use the model code and sensitive data and even provide a solid basis for legal action in case of theft.

Why is Astra Vulnerability Scanner the Best Scanner?
- We’re the only company that combines automated & manual pentest to create a one-of-a-kind pentest platform.
- Vetted scans ensure zero false positives.
- Our intelligent vulnerability scanner emulates hacker behavior & evolves with every pentest.
- Astra’s scanner helps you shift left by integrating with your CI/CD.
- Our platform helps you uncover, manage & fix vulnerabilities in one place.
- Trusted by the brands you trust like Agora, Spicejet, Muthoot, Dream11, etc.

Final Thoughts
Integrating machine learning into various applications highlights the critical need for robust security measures while developing and deploying ML models. The OWASP ML Top 10 was introduced to raise awareness of the issues plaguing ML models, like adversarial attacks or model inversion attacks, so developers and organizations can be aware of it.
Such attacks can be prevented by implementing access controls, performing adversarial training, data validation, model retraining, and other such steps. Moreover, by gaining a deeper understanding of the vulnerabilities and their resolutions through a penetration test on AI/ML models with Astra’s team, you can build more robust and resilient applications, securing both the application and the data it processes.