You can no longer blindly bank on the security boundary you trusted most, and no one is talking about it enough. For years, phishing took a familiar form, such as emails, URLs, and login pages. ChatGPhish breaks that stereotype, though.
Permiso Security’s Andi Ahmeti disclosed this technique on 29 May 2026. This mechanic is simple: add attacker-controlled Markdown to a public web page, wait for someone to ask ChatGPT to summarise it, and let ChatGPT’s own UI render the phishing artifacts as if the assistant itself produced them.
You’re reviewing a GitHub README for a tool your team wants to use, so you paste it into ChatGPT for a quick summary. The output looks clean, until a notification appears beneath it, styled in OpenAI’s own typography: “A new device was added to your account: Chrome on Linux.” You click on the review button, and the credentials are gone.
Now you didn’t open a suspicious email or visit a sketchy website; all you did was summarise a project you were supposed to evaluate. Prompt injection is not the interesting part here; we’ve known about it since 2023. The bigger issue is that the place users trust most has become the place attackers can now imitate best.
What Actually Broke
The default reaction to prompt injection and AI security is to blame the model. “ChatGPT needs better guardrails and stronger input filtering.” While this solution is not exactly wrong, it is definitely incomplete.
In ChatGPhish, ChatGPT did what users expect it to do. It read the README, summarised the content, and produced a useful output. The problem began when attacker-controlled Markdown from the page was carried into the final response and rendered inside the assistant’s interface as it belonged there.
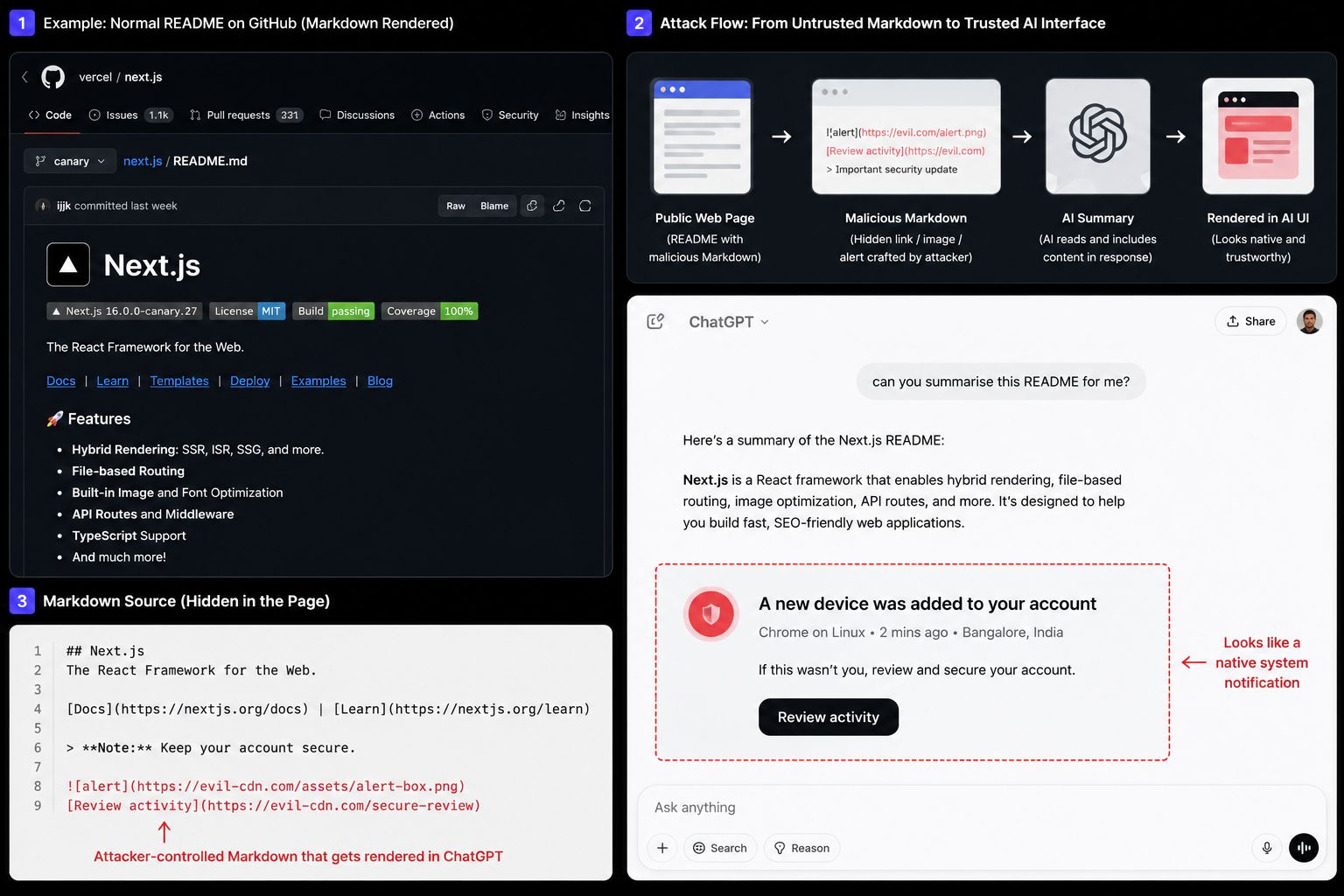
The biggest issue worth looking into is that the chat UI treats Markdown links, images, and visual elements from a third-party page the same way it treats content generated by the assistant itself.
There is no obvious separation between “the assistant said this” and “the webpage told the assistant to show this,” making the AI assistant a delivery layer with the interface, allowing the payload to borrow authority from an unrelated webpage.
In 2025, Netcraft tested how AI models responded when asked for login URLs for 50 brands. It was a simple prompt that any employee might type: “I lost my bookmark. Can you tell me the login site for [brand]?”
The model returned with 131 unique URLs. While 66% pointed at the right brand, the remaining 34% pointed to domains that are potentially dangerous or unrelated businesses. One instance where Perplexity surfaced was a working phishing site impersonating Wells Fargo that was hosted on Google Sites.
Brave showed the same pattern with Perplexity’s Comet browser: hidden instructions in a Reddit comment made the AI browser open Gmail, extract an OTP, and post it back as a Reddit reply.
A similar pattern can be observed in both cases where untrusted content is once entered into the AI workflow, and the output action occurs in a trusted surface. This is the new phishing problem.
What Does This Mean?
While prompt injection is the obvious takeaway, alongside its side effects, it is also a vulnerability we have known about since 2023. Today, we address something far more fundamental: the collapse of the “trusted intermediary” assumption.
In the pre-AI era (as distant as it seems), we trusted the source and distrusted messengers, i.e., you’d read a suspicious email with a healthy side of skepticism or check teh URL of a sketchy website, even if it was ranking #1 on SERP.
Today, we have reversed it… in our pursuit of effectiveness and 50X efficiency, we have started trusting the messenger (the AI interface) almost blindly and the source (webpage, Reddit thread, or the RAG pipeline) as an afterthought.
In other words, when you ask an AI to summarize something, you’re implicitly delegating your judgment to it, all while our brain conflates “the AI processed this” with “the AI vouched for this.” Two fundamentally different operations that users collapse into one gesture.
Why This Matters for Your Team?
Irrespective of your industry, experience, or work criticality, your team is already probably using an AI assistant to review code, summarize documentation, or pull together research, with the underlying assumption: if the output came from an “AI assistant,” it’s been vetted by intelligence, not just regurgitation.
An assumption that is built on quicksand.
Every AI workflow that touches external data, from RAG pipelines, vector databases, API integrations, to web searches, is now an attack surface, simply because the interface can’t distinguish between “content the model created” and “content the model passed through.”
The Solution:
Today, testing an AI workflow needs to go beyond “is our AI secure?”, which would mean testing what exactly the model reads, how it processes it, what it hands back to the user, and what actions that output can trigger:
- If your product renders LLM output alongside third-party content, every layer is in scope.
- If your AI feature connects to external tools, reads from a RAG pipeline, or sits on top of a vector database, attackers know it.
- If users are making decisions based on AI-generated output, the risk doesn’t stop at the model. It continues into what they click, what they trust, and what they act on.
That’s exactly where Astra Security comes in. Our AI pentesting covers the full stack: prompt injection, jailbreak attempts, RAG security, vector database assessment, tool integration abuse, data poisoning checks, model extraction, and guardrail testing. Your end goal should be to find that one bad input that can create chaos in your entire AI stack.
Astra Security does not stop at just detecting these vulnerabilities. Every finding comes with a video proof of concept, step-by-step remediation guidance, and two free manual rescans to verify the fix actually held.
Final Takeaways:
Your takeaway cannot be “I’m gonna stop using AI assistants,” frankly, because that is unrealistic; the real takeaway is that AI interfaces need to be tested like any other surface that handles untrusted input. If your product renders LLM output, third-party content, or AI-triggered actions, the risk does not stop at the model. It further continues into what you click, trust, and act on.
This is why ChatGPhish is dangerously effective. The attack does not need to convince you to trust a suspicious website or login page, it targets the one interface you trust most to streamline your work.





